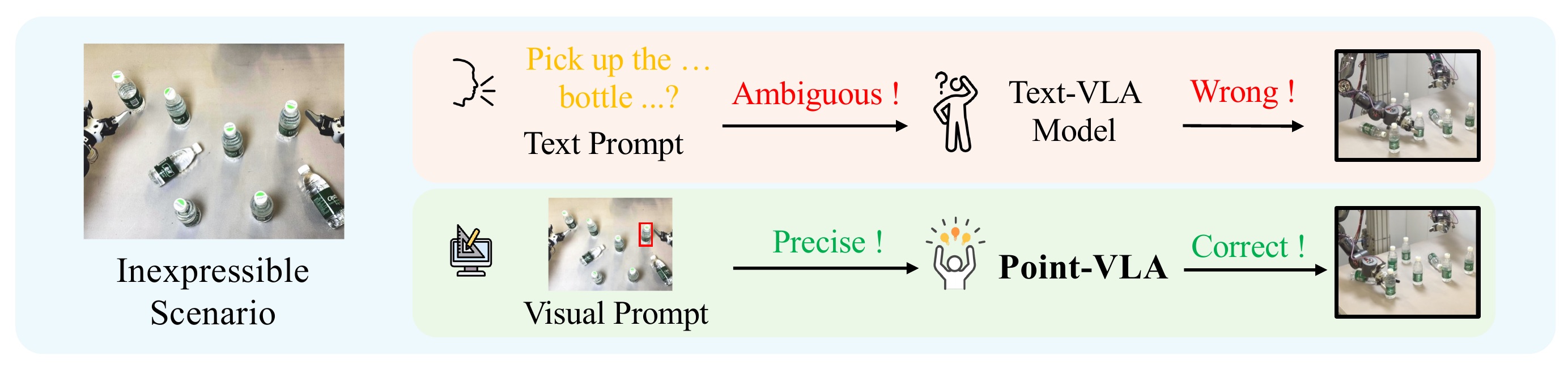
Vision-Language-Action (VLA) models align vision and language with embodied control, but their object referring ability remains limited when relying solely on text prompts, especially in cluttered or out-of-distribution (OOD) scenes.
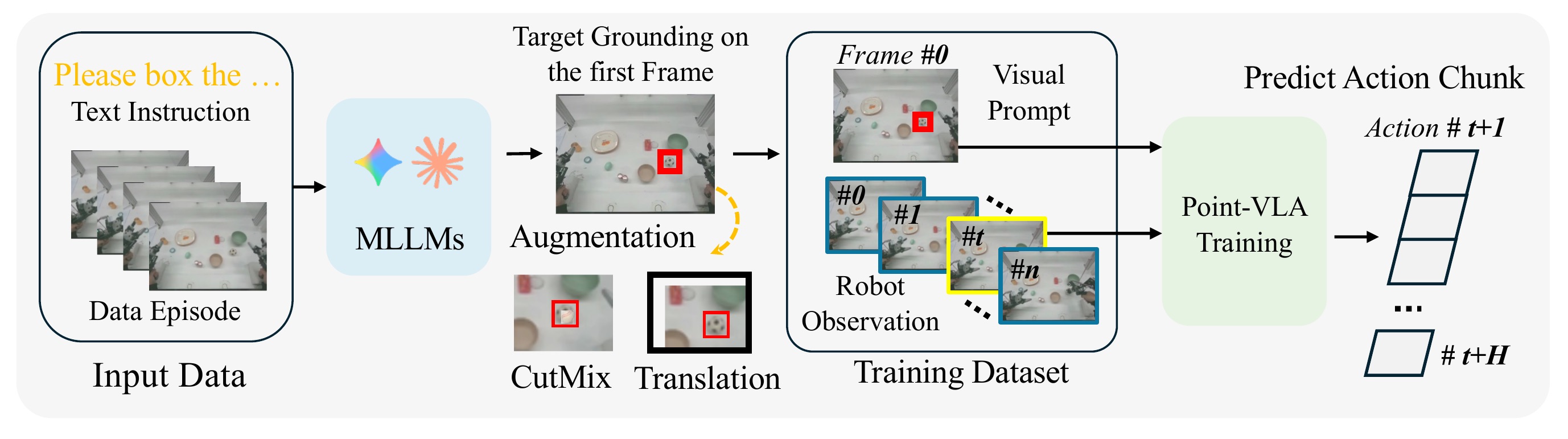
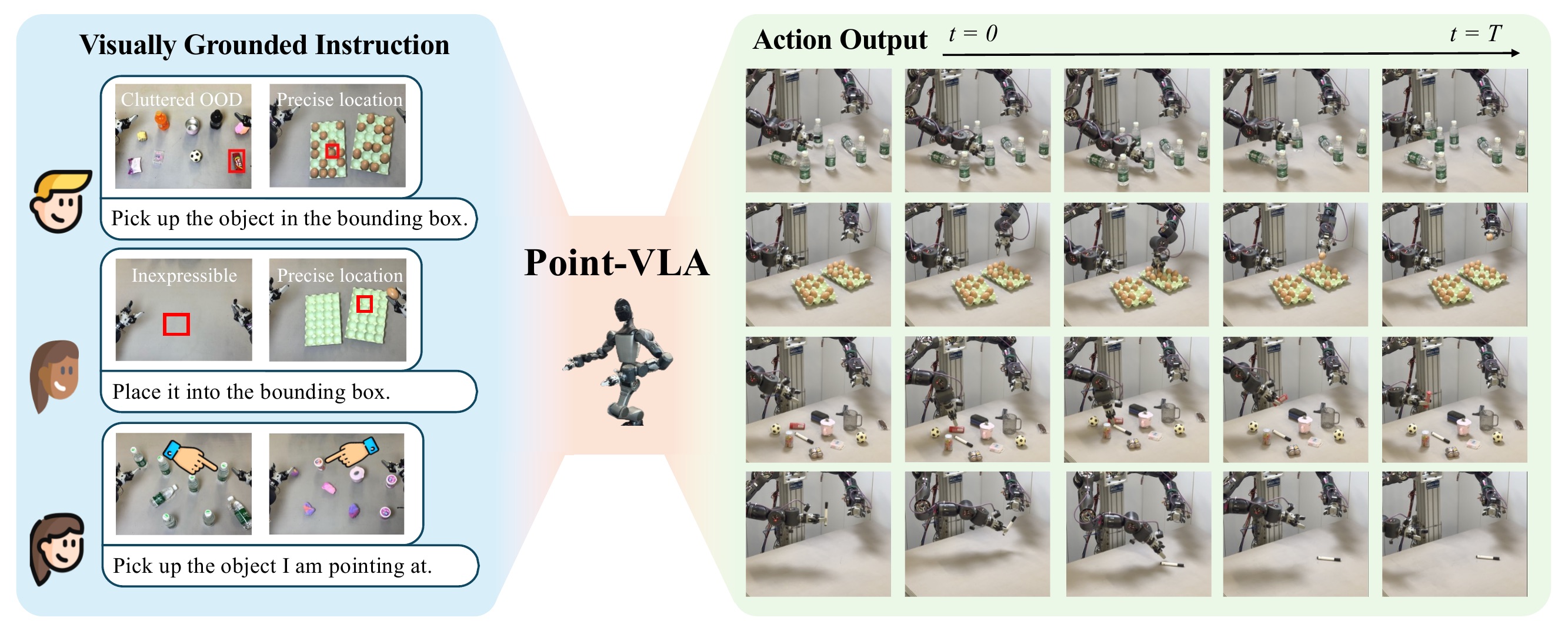
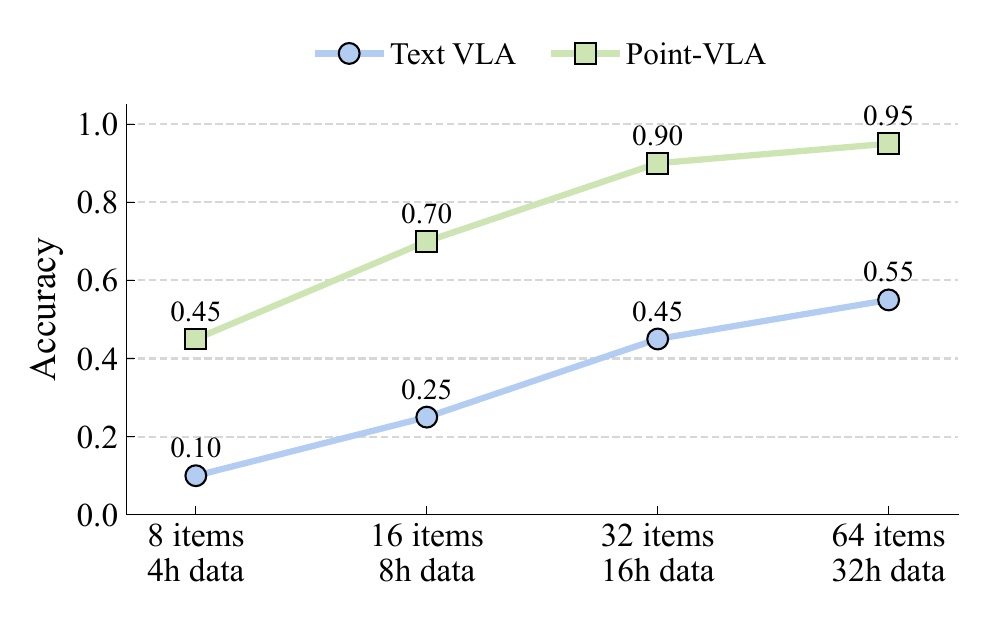
In this study, we introduce Point-VLA, a plug-and-play policy that augments language instructions with explicit visual cues (bounding boxes) to resolve referential ambiguity and enable precise, object-level grounding. To efficiently scale visually grounded datasets, we further develop an automatic data annotation pipeline requiring minimal human effort.
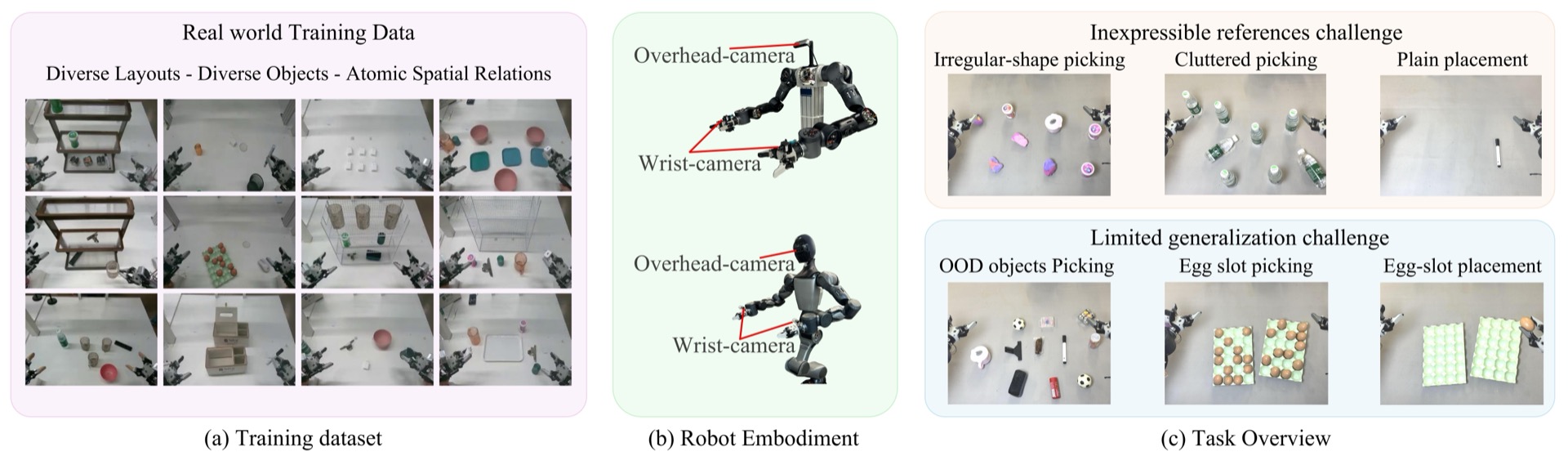
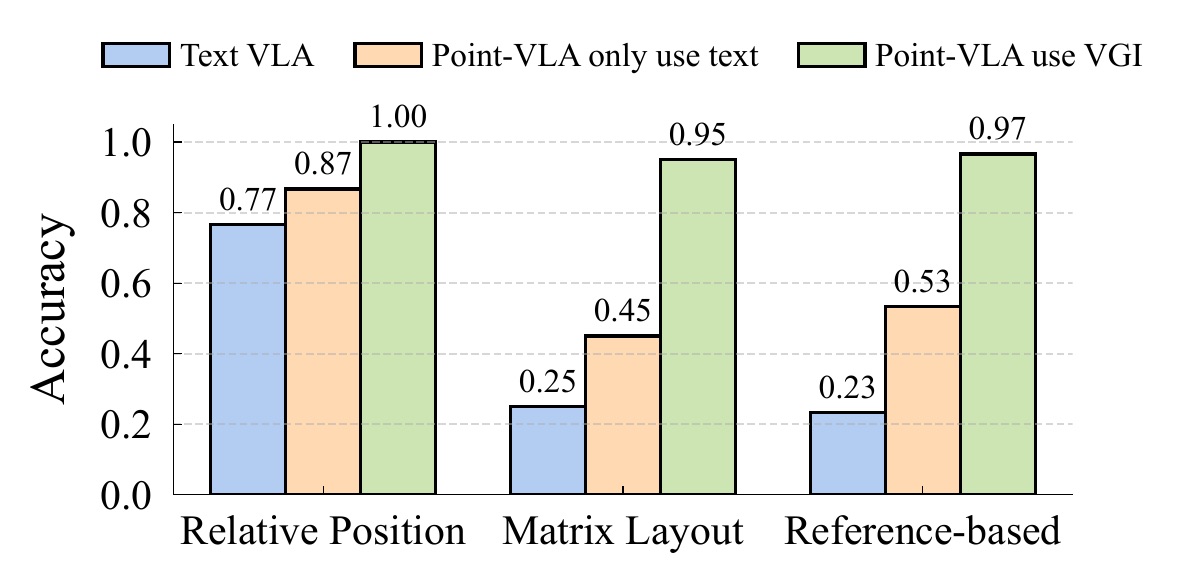
We evaluate Point-VLA on diverse real-world referring tasks and observe consistently stronger performance than text-only instruction VLAs, particularly in cluttered or unseen-object scenarios, with robust generalization. These results demonstrate that Point-VLA effectively resolves object referring ambiguity through pixel-level visual grounding, achieving more generalizable embodied control.